






TL;DR
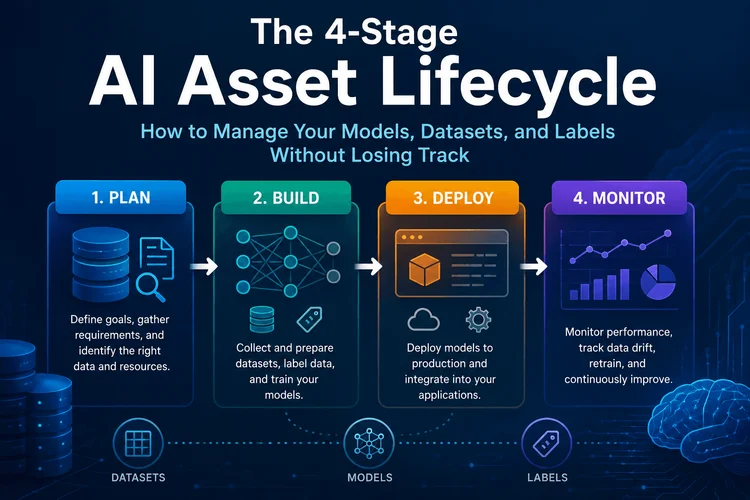
Every machine learning project produces three core assets: labeled datasets, trained models, and the schemas that define how labels are structured. Most teams manage code with Git, infrastructure with Terraform, and models with… nothing systematic. The result is duplicated work, untraceable training data, models in production that nobody can reproduce, and compliance gaps that surface at the worst possible time. This article introduces a 4-stage lifecycle framework (Create, Version, Deploy, Retire) designed specifically for AI assets, walks through each stage with concrete practices, and explains why 2026 is the year this stops being optional.
Why AI Assets Are Different From Code
Software engineers solved the asset management problem decades ago. Code lives in Git. Dependencies live in lock files. Infrastructure lives in declarative configs. The entire state of a software system can be reconstructed from version-controlled artifacts.
AI systems break this model. A trained model is not just code. It is the product of code, data, hyperparameters, compute environment, training duration, and random seed. Change any one of those inputs and you get a different model. Two engineers running the same training script on the same data can produce models with measurably different behavior if the environment is not fully controlled.
Labeled datasets add another layer of complexity. Labels change over time. Annotators correct mistakes. Schema definitions evolve as the team learns what the model actually needs. A dataset that was “complete” in January may be materially different by March, and if nobody tracked the changes, reproducing the January model becomes impossible.
This reproducibility problem is well documented. A 2022 paper from Princeton and Stanford found that only 4 out of 50 surveyed ML papers provided sufficient artifacts to reproduce their results. The gap between research and production is even wider.
For developers who have seen similar infrastructure challenges in traditional software, the core issue is familiar: building AI products requires much more than connecting an API. The same principle applies to managing the artifacts those products produce.
The 4-Stage AI Asset Lifecycle
The lifecycle framework below applies to all three asset types: datasets, models, and label schemas. Each stage has specific practices, tools, and failure modes.
Stage 1: Create
What happens: A new dataset is labeled, a model is trained, or a label schema is defined for a new document type or task.
The common failure: The asset is created in a local environment with no metadata attached. The engineer who built it knows the context. Nobody else does.
What good looks like:
Every asset gets a creation record that includes:
The key principle at the Create stage is that no asset should exist without provenance. If you cannot answer “where did this come from and how was it built?” then the asset is a liability, not a resource.
Research supports this rigorously. As covered in the hidden cost of noisy training data, even a 3.4% label error rate across benchmark datasets (confirmed by MIT’s 2021 study of 10 major ML datasets) causes measurable model degradation. Tracking quality baselines at creation is the only way to catch this before training.
Stage 2: Version
What happens: The asset changes. Labels get corrected. New training data is added. A model is retrained with updated hyperparameters. A label schema adds a new class.
The common failure: The new version overwrites the old one. Or it gets saved as model_v2_final_FINAL.pt. Or the dataset is updated in place with no record of what changed.
What good looks like:
Dataset versioning requires tracking three distinct change types:
For models, versioning means storing the full training artifact (weights, config, evaluation results) alongside a pointer to the exact dataset version used. The model and dataset versions must be linked bidirectionally. You should be able to answer both “what dataset produced this model?” and “what models were trained on this dataset?” at any time.
Tool landscape in 2026: DVC (Data Version Control) handles dataset versioning with Git-like semantics. MLflow and Weights & Biases track experiment metadata and model artifacts. LakeFS provides Git-like branching for data lakes. However, none of these tools fully solve the label schema versioning problem out of the box, which is why teams often build custom lineage tracking for annotation-specific workflows.
Stage 3: Deploy
What happens: A model moves from development into a production environment where it serves predictions to users or downstream systems.
The common failure: The model is deployed without a record of which dataset version it was trained on, which evaluation thresholds it passed, or what its known failure modes are. When the model starts producing unexpected outputs in production, the team cannot determine whether the issue is a data problem, a model problem, or an environment problem.
What good looks like:
A deployment record ties together:
The EU AI Act, whose risk-based framework began enforcement in 2025, explicitly requires organizations deploying high-risk AI systems to maintain records of training data, model performance, and decision-making processes. According to the European Commission’s AI Act documentation, high-risk systems must have “traceability of results” and documentation of “the datasets used for training, validation and testing.” This makes deployment-stage lineage tracking a legal requirement for organizations operating in or serving EU markets.
Even outside regulatory requirements, deployment without lineage creates a practical problem: model debugging becomes guesswork. When a model in production starts misclassifying a specific document type, the team needs to trace back through the deployment record to the training data to determine whether the issue is a label quality problem, a distribution shift, or a model architecture limitation. This is especially critical as AI-first development workflows accelerate the pace at which models move from code to production.
Stage 4: Retire
What happens: A model is removed from production. A dataset is superseded by a newer, higher-quality version. A label schema is deprecated in favor of a revised taxonomy.
The common failure: Retired assets are deleted or abandoned without any record. Months later, someone needs to understand why a specific model was making certain predictions during a specific time period, and the artifacts no longer exist.
What good looks like:
Retirement is not deletion. It is archival with context.
A retirement record includes:
For datasets specifically, retirement also means documenting whether the labeled data was merged into the successor dataset, discarded, or kept as a separate historical artifact. Label corrections from the retired dataset should propagate forward, not disappear.
The Practical Problem: Why Teams Skip This
The honest answer is that lifecycle management feels like overhead when you are under pressure to ship.
A 2025 survey by Gartner found that only 54% of AI projects move from pilot to production. The pressure to demonstrate value quickly pushes teams to optimize for speed over traceability. And for small teams, the tooling burden of maintaining versioning, lineage, and deployment records can feel disproportionate to the immediate benefit.
But the cost of skipping lifecycle management compounds over time:
McKinsey’s 2025 AI report found that 78% of organizations now use AI in at least one business function, but scaling AI effectively remains the primary challenge. Lifecycle management is one of the structural reasons that scaling fails.
What a Minimum Viable Lifecycle Looks Like
Not every team needs enterprise MLOps infrastructure on day one. Here is a minimum viable lifecycle that works with existing tools:
For datasets:
For models:
For label schemas:
This minimum setup can be implemented in a single afternoon and prevents the worst failure modes described above.
Where This Is Heading in 2026 and Beyond
Three trends are converging to make AI asset lifecycle management a non-negotiable practice:
Regulatory pressure is increasing. The EU AI Act is the most prominent example, but similar frameworks are emerging in the US (NIST AI Risk Management Framework), Canada (AIDA), and across Asia-Pacific markets. All of these frameworks require some form of training data documentation and model traceability.
Data-centric AI is the new default. The research community has shifted from model-centric approaches (build a bigger model) to data-centric approaches (improve the data). This shift puts labeled datasets at the center of the ML workflow, and datasets that are not versioned, documented, and quality-controlled become the bottleneck. Even teams building LLM-powered tools with function calling depend on high-quality labeled data for evaluation and fine-tuning.
Team sizes are growing. As AI moves from research labs to product teams, the number of people touching datasets, models, and schemas increases. Without lifecycle management, coordination breaks down the moment a second engineer joins the project. Teams adopting human-AI collaborative workflows need asset tracking that scales with collaboration, not against it.
For teams working with document AI specifically, where PDF files are labeled with structured annotations for training layout detection and text extraction models, the lifecycle challenge is amplified by the complexity of the source material. A single legal contract or financial report can produce dozens of labeled regions across multiple pages, and the label schema needs to account for document hierarchy, spatial relationships, and domain-specific categories. Managing these assets at scale requires purpose-built workflows, and the emerging discipline of AI asset management addresses exactly this gap by providing structured frameworks for organizing, versioning, and maintaining AI training assets across their full lifecycle.
Frequently Asked Questions
What is an AI asset?
An AI asset is any artifact produced during the machine learning workflow that has reuse value. This includes labeled datasets, trained model weights, label schemas, evaluation benchmarks, preprocessing pipelines, and feature engineering code. The defining characteristic of an AI asset is that it took meaningful time and resources to create and would be costly to reproduce from scratch.
How is dataset versioning different from code versioning?
Code changes are typically small, text-based diffs that Git handles well. Dataset changes involve large binary files, statistical distribution shifts, and label corrections that affect the meaning of existing data rather than adding new data. Standard Git cannot track the difference between “we added 500 new labeled images” and “we corrected 200 existing labels,” but that distinction is critical for understanding how a dataset evolves.
Do I need dedicated MLOps tooling to implement lifecycle management?
No. A minimum viable lifecycle can be implemented with structured directories, a changelog, and a spreadsheet. The benefit of dedicated tools like DVC, MLflow, or LakeFS is that they automate lineage tracking and reduce the manual overhead as the team and dataset scale. Start simple and add tooling when the manual approach becomes a bottleneck.
What happens if I skip lifecycle management and need to audit my models later?
You face an expensive and often incomplete reconstruction process. Determining which data trained a production model, what label corrections were made between versions, or why a specific model was retired requires artifacts that no longer exist if they were never recorded. In regulated industries, this gap can result in compliance failures.
How does the EU AI Act affect AI asset management?
The EU AI Act requires providers of high-risk AI systems to maintain technical documentation covering training data, model design, evaluation results, and post-deployment monitoring. Article 11 specifically requires “data governance and management practices” for training, validation, and testing datasets. Organizations that cannot produce this documentation face penalties of up to 35 million euros or 7% of global annual turnover, whichever is higher.
Can lifecycle management help with model debugging?
Yes, and this is one of its most practical benefits. When a production model starts underperforming, the deployment record links the model to its training data version, which links to the label schema version and the original annotations. This chain of custody allows the team to determine whether the issue is a training data problem, a distribution shift, a schema change, or a model architecture limitation, rather than investigating all possibilities simultaneously.
Conclusion
Managing AI assets is not a glamorous part of the machine learning workflow. It does not involve novel architectures, impressive benchmarks, or breakthrough research. What it does involve is the structural discipline that separates teams who can reproduce, audit, and improve their models from teams who cannot.
The 4-stage lifecycle framework (Create, Version, Deploy, Retire) is not a product recommendation. It is a set of practices that any team can implement with existing tools, starting today. The cost of not implementing it is measured in duplicated training runs, unresolvable production bugs, compliance gaps, and institutional knowledge that walks out the door every time a team member leaves.
In 2026, with regulatory frameworks tightening, data-centric AI becoming the default paradigm, and AI teams growing beyond single-engineer projects, lifecycle management is no longer optional infrastructure. It is the foundation that everything else depends on.